The use of transforms in data compression algorithms is at least 40 years old. The goal of this three-part series of posts is to provide the mathematical background necessary for understanding transforms and to explain why they are a valuable part of many compression algorithms.
I’m focusing on video since that’s my particular interest. Part 1 reviewed vectors, the dot product and orthonormal bases. Part 2 introduced the use of matrices for describing both one and two-dimensional transforms. Finally, Part 3 (this post) gives an example and explains intuitively why transforms are a valuable part of video compression algorithms.
Now that we have stepped through some of the rationale behind simple transforms and contemplated how transforms can be applied to two-dimensional input matrices, it is time to discuss the basis for almost all media compression — the discrete cosine transform, or DCT.
The basis vectors for the size N DCT transform are given by
\underline{u}_{k}^{T}=\alpha (k) \cos (\dfrac{\pi k}{N}j+ \dfrac{\pi k}{2N})
where j indexes the vector column and
\alpha(k)= \begin{Bmatrix} 1/\sqrt{N} \space for \space k=0 \\ \sqrt{2/N} \space otherwise \end{Bmatrix}
Of course, both k and j vary from 0 to N-1 (recall that k indexes the transform matrix row). The following matrix therefore defines the size 4 DCT transform:
A= \begin{pmatrix} 0.5 & 0.5 & 0.5 & 0.5 \\ 0.6532 & 0.2706 & -0.2706 & -0.6532 \\ 0.5 & -0.5 & -0.5 & 0.5 \\ 0.2706 & -0.6532 & 0.6532 & -0.2706 \end{pmatrix}
If you want to practice your matrix math, compute AAT for this matrix and verify that you get the identity matrix I.
If you study the formula for the DCT basis vectors, you’ll see that they are sinusoid — as k increases, the frequency increases. All the values in row zero of the transform matrix are constant and each subsequent row has a higher frequency than the one above it. You will also see that each sinusoid has a phase shift that depends on k.
What do the basis matrices look like? Recall from eq. 5 of the last post that the i,j’th basis vector is given by the vector product
B_{i,j}=\underline{u}_{i}\underline{u}_{j}^{T}
A few representative basis matrices are shown below to provide a flavor for their structure.
B_{0,0}= \begin{pmatrix} 0.25 & 0.25 & 0.25 & 0.25 \\ 0.25 & 0.25 & 0.25 & 0.25 \\ 0.25 & 0.25 & 0.25 & 0.25 \\ 0.25 & 0.25 & 0.25 & 0.25 \end{pmatrix}B_{0,3}= \begin{pmatrix} 0.1353 & -0.3266 & 0.3266 & -0.1353 \\ 0.1353 & -0.3266 & 0.3266 & -0.1353 \\ 0.1353 & -0.3266 & 0.3266 & -0.1353 \\ 0.1353 & -0.3266 & 0.3266 & -0.1353 \end{pmatrix}
B_{0,3}= \begin{pmatrix} 0.1353 & 0.1353 & 0.1353 & 0.1353 \\ -0.3266 & -0.3266 & -0.3266 & -0.3266 \\ 0.3266 & 0.3266 & 0.3266 & 0.3266 \\ -0.1353 & -0.1353 & -0.1353 & -0.1353 \end{pmatrix} =B_{0,3}^{T}
B_{3,3}= \begin{pmatrix} 0.0732 & -0.1768 & 0.1768 & -0.0732 \\ -0.1768 & 0.4267 & -0.4267 & 0.1768 \\ 0.1768 & -0.4267 & 0.4267 & -0.1768 \\ -0.0732 & 0.1768 & -0.1768 & 0.0732 \end{pmatrix}
In general, the basis matrices exhibit sinusoidal behavior on their rows, on their columns or on both. This makes sense when you consider that each is the product of two sinusoidal vectors! The picture below shows all 16 of the basis matrices in pictorial form. In this picture, values that have a reddish hue are negative, while grayscale values are positive. The “whiter” a grayscale value, the larger the positive number it represents, while the brighter red a value, the smaller the negative number it represents.
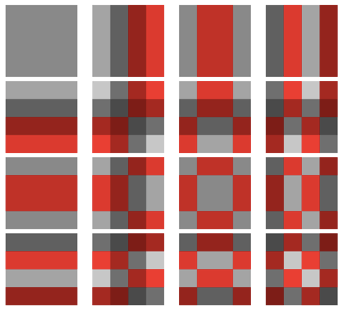
So why is it useful to transform blocks of data from an image as part of a compression algorithm? First, any image can be partitioned into non-overlapping blocks of size N:N pixels (in our case 4-by-4). Each block comprises 16 numbers, so we need to communicate an approximation of all 16 of these numbers to a receiver in order to reconstruct an approximation of the block. Without compression, we would just send each of the 16 numbers separately. Can we get by with sending fewer numbers?
Consider the special case where a block to be compressed is exactly equal to a scaled version of one of our basis matrices. In this case, in order to communicate all 16 image numbers to a receiver, we only need to send the position of the retained basis matrix and the scale factor to apply to it. In the general case, if a 4:4 image block can be closely approximated by a linear combination of just a few of the basis matrices, then it is desirable to transform the block first and just send the scale factors and positions of the appropriate basis matrices. (Note that worst case the positions of the retained basis matrices can be sent using 16 bits, one bit for each position. In practice, there are even more efficient ways to do it.)
For a specific example, assume the following 4-by-4 block is a group of 16 pixels from an 8-bit black-and-white image. Note that the block corresponds to a darker region in the lower lefthand corner and a brighter region in the upper righthand corner:
X= \begin{pmatrix} 45 & 100 & 140 & 160 \\ 50 & 104 & 160 & 200 \\ 36 & 68 & 146 & 194 \\ 53 & 28 & 71 & 110 \end{pmatrix} 
The transform of this block is shown below:
Y= \begin{pmatrix} 416.2 & 186.1 & 7.7 & 5.9 \\ 69.2 & -21.2 & -36.4 & -14.8 \\ -62.8 & 51.3 & 6.7 & 1.7 \\ 1.9 & -17.3 & -3.6 & 3.2 \end{pmatrix}
Now, what do we get if we keep only the five largest values in Y and inverse transform them? In other words, what do we get if we inverse transform the matrix below?
\widetilde{Y}= \begin{pmatrix} 416.2 & -186.1 & 0 & 0 \\ 69.2 & 0 & 0 & 0 \\ -62.8 & 51.3 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{pmatrix}
Computing the inverse transform with just these five components is equivalent to approximating the original data by a linear combination of only five of the sixteen basis matrices. We get the following result:
\widetilde{X}= \begin{pmatrix} 67 & 93 & 129 & 155 \\ 52 & 97 & 161 & 207 \\ 33 & 78 & 143 & 188 \\ 22 & 48 & 84 & 110 \end{pmatrix} 
Although many of the individual pixel values in this approximation are no longer exactly the original value, the basic visual impression is preserved: The lower lefthand portion of the approximation is darker than the upper righthand portion.
A good transform for a particular signal packs most of the signal’s energy into the upper lefthand side of Y. The best transform for a given signal depends on the signal’s statistics. It turns out that the DCT is a particularly good transform for the statistics of images — and there is a computationally fast algorithm for its calculation, which is important in real-world applications.
Now, imagine that you can adaptively decide which components of Y to keep on a block-by-block basis — and that the choice of which coefficients you kept can be efficiently communicated to a receiver — and that the quantizer step size you used on each retained Y component can vary depending on its position. At that point, you are well on your way to understanding MPEG-2, H.264, and similar transform-based algorithms!
This entire series of blog posts is also available as a Cardinal Peak white paper.