When Covestro, a global leader in high-tech polymer materials, needed to accelerate their R&D cycle, they leveraged their strategic partnership with Cardinal Peak / FPT Software. Building on our deep institutional knowledge of their application ecosystem, we engineered a secure, scalable Generative AI for R&D solution—a “Digital Chemist”—that allows scientists to programmatically query decades of unstructured testing data, reducing research time by 50%.
When Covestro, a global leader in high-tech polymer materials, needed to accelerate their R&D cycle, they leveraged their strategic partnership with Cardinal Peak / FPT Software. Building on our deep institutional knowledge of their application ecosystem, we engineered a secure, scalable Generative AI for R&D solution—a “Digital Chemist”—that allows scientists to programmatically query decades of unstructured testing data, reducing research time by 50%.
The Challenge: “Dark Data” in the Lab
Covestro possessed a goldmine of proprietary data: 30 years of PDF reports, Excel spreadsheets, and Word documents detailing thousands of chemical formulations. However, this data was “dark”—unstructured, unsearchable, and scattered across siloed drives.
- The Search Barrier: Scientists spent hours manually digging through folders to find past experiments, often re-running expensive tests because previous results couldn’t be located.
- The Security Gap: Off-the-shelf GenAI tools were non-starters; Covestro could not risk exposing proprietary formulations to public models.
- The Complexity: Chemical data is contextual. A standard keyword search for “Polymer X” returns thousands of irrelevant hits without understanding the relationship between formulations and results.
One of the factors that makes this partnership amazing is the flexibility, the speed, and the diligence of the team.
The Solution: A Secure RAG Architecture
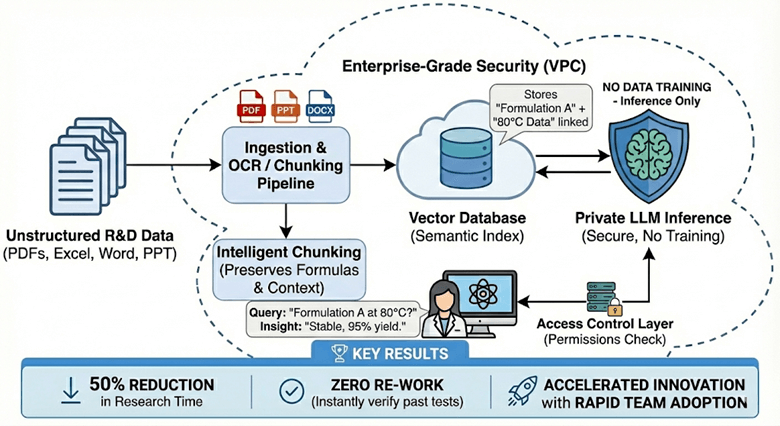
Leveraging our AI Center of Excellence (CoE), we architected a custom Retrieval-Augmented Generation (RAG) solution that acts as a secure “Digital Chemist” assistant.
Data Ingestion & "Chunking"
We engineered an automated ingestion pipeline to process the ‘messy’ reality of R&D data. The system ingests PDFs, PPTs, and DOCX files—including complex Safety Data Sheets (SDS)—utilizing advanced computer vision to distinguish between text, chemical diagrams, and tables. We implemented intelligent ‘chunking’ strategies that respect the structure of scientific documents, ensuring that chemical formulas and their associated results stay semantically linked in the vector database.
Vector Search & LLM Integration
We utilized a high-performance vector database to index the semantic meaning of the documents. When a scientist asks, “How did Formulation A perform at 80°C?”, the system retrieves the specific paragraphs containing that thermal data and feeds them into a secure, private instance of a Large Language Model (LLM).
Enterprise-Grade Security
Security was paramount. We deployed the solution within a Virtual Private Cloud (VPC), ensuring that:
- No Data Training: The LLM is used only for inference (reasoning), not training. Covestro’s data never leaves their secure environment.
- Access Control: The system respects existing file permissions—scientists can only query documents they are authorized to view.
Covestro’s proprietary chemical data is never used to train base models, ensuring that a competitor using the same LLM can never access Covestro’s unique research insights.
RAG Architecture Diagram
The Results: 50% Faster Innovation
By transforming dark data into an interactive knowledge base, we fundamentally changed the daily workflow of Covestro’s scientists.
- 50% Reduction in Research Time: Questions that took days to answer via manual search are now resolved in seconds.
- Zero “Re-Work”: Scientists can instantly verify if an experiment has been run before, saving thousands of dollars in wasted materials and lab time.
- Adoption at Scale: The tool was rapidly adopted by the R&D team, becoming a central part of their innovation process for chemical formulation optimization.
Core Tech
Generative AI, RAG (Retrieval-Augmented Generation), LLM
Cloud Infrastructure
AWS (Bedrock, Lambda, OpenSearch)
Data Processing
Python, LangChain, OCR
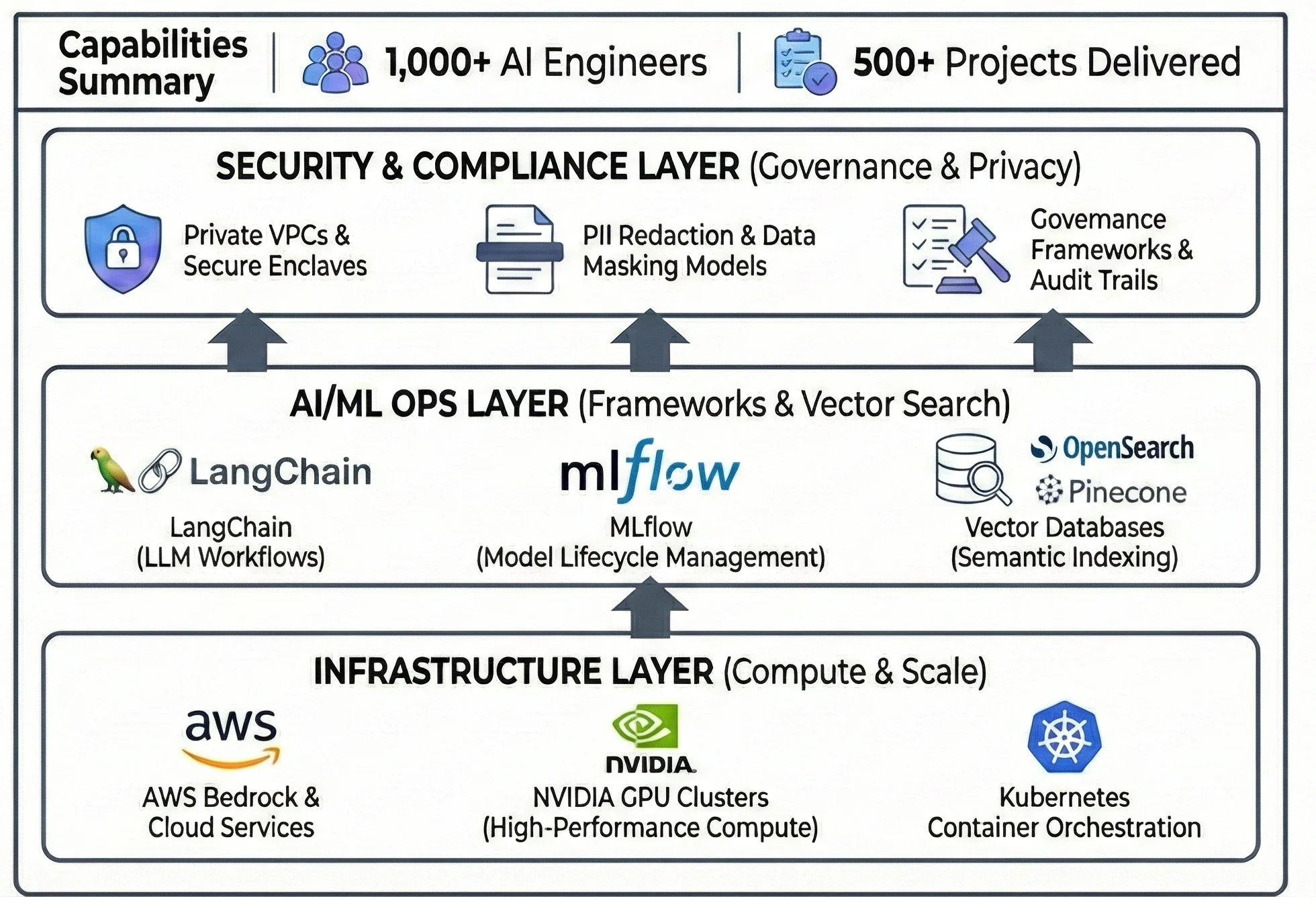
The Engine Behind the Solution
This project was accelerated by our AI Center of Excellence (CoE). By leveraging pre-built accelerators, proven MLOps frameworks, and a deep bench of 1,000+ AI engineers, we delivered an enterprise-grade, secure RAG solution in a fraction of the time required for a ground-up build.
The GenAI Accelerator Stack
Explore Materials Informatics & GenAI Related Solutions

Generative AI Services
Learn how we build custom LLM applications that are secure, scalable, and private.


Market: AI for Materials Science
Discover other ways we are helping the chemical and materials industry innovate faster.
Generative AI for R&D Frequently Asked Questions
Can Generative AI (LLMs) be used securely with proprietary corporate R&D data?
Yes, Gen AI (LLMs) can be used securely with proprietary corporate R&D data if architected correctly. It requires an “inference-only” approach within a secure environment (like a Virtual Private Cloud), ensuring your proprietary data is never used to train public models. Leading enterprises use Retrieval-Augmented Generation (RAG), where the AI is granted temporary access to internal documents to answer a specific query without absorbing the data into its core model.
How do you prevent AI models from "hallucinating" incorrect scientific facts or chemical formulas?
In scientific contexts, relying on an LLM’s general knowledge is risky. The solution is a strict RAG architecture. The model must be instructed to only generate answers based on facts retrieved from a verified internal knowledge base (like a vector database of verified reports) and to provide citations for every claim, allowing scientists to instantly verify the source.
Additionally, because our RAG architecture utilizes intelligent chunking that understands document structure, the system can reliably retrieve data from Safety Data Sheets (SDS) without losing the context of the chemical properties listed.
What is the best way to digitize unstructured scientific legacy data like PDFs and handwritten lab notes for AI?
Standard OCR is often insufficient for complex scientific documents. A robust data engineering pipeline is required, utilizing advanced computer vision to recognize document structure ( differentiating between text, chemical diagrams, and tables) and intelligent “chunking” strategies to preserve the semantic context of the data before it is ingested into a vector database.
What is the role of a Vector Database in a RAG architecture for R&D?
A vector database is essential for searching unstructured scientific data. Unlike standard keyword search, it stores the “semantic meaning” of data as mathematical vectors. This allows an R&D system to understand contextual relationships between chemical formulations, test parameters, and results across thousands of disparate PDF reports, retrieving the exact context needed to answer complex scientific queries.
Why use AWS Bedrock for building secure enterprise Generative AI applications?
AWS Bedrock is often chosen for enterprise applications because it provides secure, private access to leading foundation models via a single API. Crucially for R&D, Bedrock ensures data privacy: your proprietary data used for inference is encrypted, remains within your Virtual Private Cloud (VPC), and is never shared with model providers or used to train their public base models.