While a queue data structure offers numerous benefits, choosing the right queue for your application remains a challenge. In part one of this blog series, we gave a little queue computer science 101 background, detailing what queues are and describing a few different queue data structure types. In this second part of the series, we’ll dive into different queuing use cases before concluding the series with cost drivers to consider and best practices to follow when choosing a queue.
Now that we know queues are data structures that order elements/items in a sequence, we can discuss what queue data structures are actually used for in computing.
Contents
What are Queues Used For?
Common in computer programs, queues can be used for any situation where you want things to happen in the order that they were called but where the computer is not speedy enough to keep up. Once a new element is inserted into a queue data structure, every element inserted before the new element in the queue must be removed in order to remove the newly added element. Such situations arise in almost every type of software development.
Consider a website that serves files to thousands of users or an operating system that is capable of multitasking as examples. In operating systems, queues are used to control access to shared resources, such as printers, files and communication lines. Queues are the most appropriate data structure for these examples because:
- a website cannot service all requests, so it handles them in order of arrival on a first-come-first-served basis.
- an operating system cannot run all jobs simultaneously, so it schedules them according to some policy.
In computing systems that involve high throughput and massive scale-out, queues are like a temporary database behind the scenes. By managing elements in the same manner a database would, if the service fails, a durable queue can reconstruct where it was and ensure items get delivered. Let’s take a look at some other queue applications.
Messaging Queues
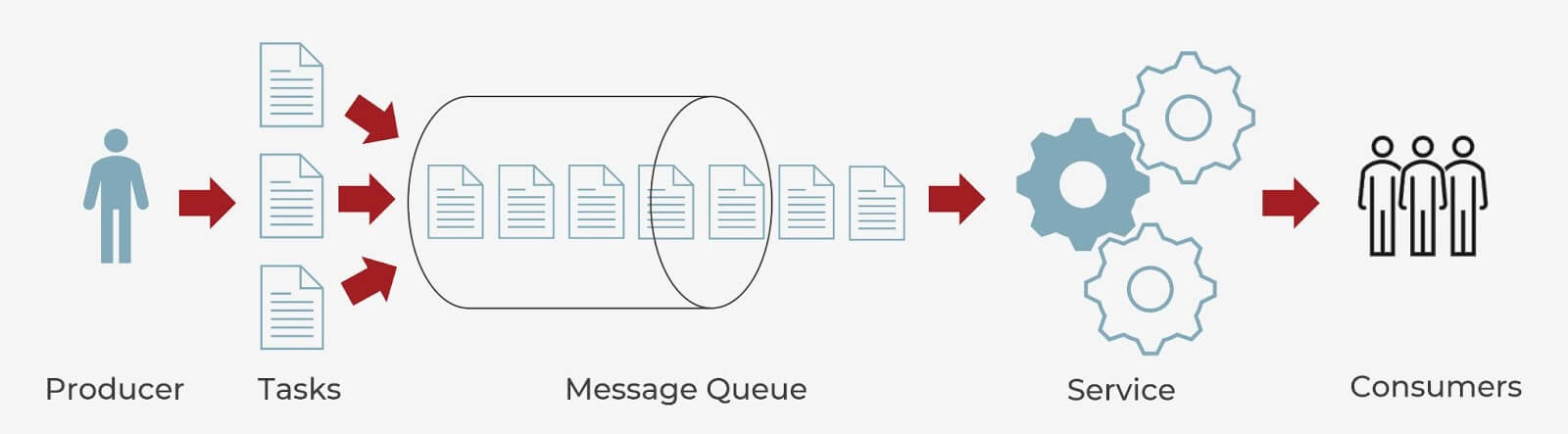
When it comes to modern cloud architecture, queues are used typically for cross-service communication. Messages (requests, replies, events, jobs, error messages or just plain information) are stored on the queue data structure until they are processed by a consumer and deleted, allowing different parts of a system to communicate and process operations in an asynchronous manner.
Subscribers to a service access queues to exchange data using point-to-point or publish-subscribe patterns. Point-to-point communications enable many producers and consumers to use the queue, but each message is processed only once, by a single consumer. In a pub-sub pattern, messages can be processed by more than one consumer.
Since cloud applications are often decoupled into smaller, independent building blocks that are easier to develop, deploy and maintain than one large application, message queues provide communication and coordination for these distributed applications, which simplifies coding while improving performance, reliability and scalability.
Queues in Big Data
In the case of big data, queues are typically gathering data from a myriad of different sources in order to analyze that information and improve a product or service. When collecting data from several different clients or edge services, that information tends to be incredibly valuable and difficult to reconstruct. As such, it’s important that data is durably maintained and guaranteed to be delivered.
When used for applications in big data, queue data structures receive messages containing the data required by the service from tasks, and the queue acts as a buffer, storing the message until the service retrieves it. One benefit of using a queue that acts as a buffer is that it enables that queue to level intermittent heavy loads that can cause the service to fail or the task to time out. By decoupling the tasks from the service, the service can handle the messages at its own pace without regard to the volume of requests from concurrent tasks, helping to maximize availability and scalability while better controlling costs.
Additionally, queues are often used in big data to create extract-transform-load (ETL) pipelines in which you’re ingesting the content in a common way. In an ETL pipeline, everybody writes to the queue, and the data is being transformed in some way, whether normalizing the data to one type of data format or augmenting data with extra metadata or information on the side and loading it off into a database or a data store downstream for future analytics, etc.
In short, big data is one queue data structure use case where queues are used as both a job in terms of transforming the data but also as a load-leveling and distribution pipeline.
Application Integration Queues
Even the most basic web-based systems design requires queues to be used in order to integrate applications. While queues in application integration use cases tend to be thought of more as messaging or messaging brokers, the same idea holds true. A job, message or event can be put into a queue and then can be consumed by a different service or multiple services depending on the queue or message broker’s capability to distribute those events and send back responses if need be.
As an example, I’ve been involved with projects in which a queue was used to buffer audio data out of a data acquisition card. One project, in particular, saw hardware generating audio samples at a rapid rate, and the project required all of that information to be captured in memory so that it could be sent out for recording to disk or streamed to a remote client/whoever else is interested.
In reality, the prime advantage of an application-level queue is the decoupling of all the different services but allowing the applications to still integrate together in a consistent way. Decoupling enables the following:
- more functionality and applications to be added in the system without having to make changes to the existing code
- increased ability to modify parts of the app without impacting another
- opportunities to add more instances or processing to better handle increased load
- the ability to try different message delivery topologies in order to achieve complex process orchestration and organically grow the system
- back-end systems to be protected from unexpected surges in front-end traffic
Many types of business software typically cannot communicate with one another, and the lack of communication often leads to inefficiencies, wherein identical data is stored in multiple locations or straightforward processes are unable to be automated. Utilizing queues to link applications together simplifies — to the greatest extent possible — the automation of business processes while simultaneously avoiding the need to make sweeping changes to the existing applications or data structures.
These are all very useful things, but a word of caution: While the decoupling effect of a queue between code or services is what makes it so powerful for application integration, this decoupling can also make it extremely difficult to troubleshoot queue-driven applications — particularly when there are multiple publishers. Tracking down the sender of a message to understand bad behaviors in response to the message can be painfully difficult. Of course, there are ways to manage this, but be aware that queues push everything to asynchronous handling of data and events, which can lead to race conditions and other often difficult-to-track problems. Consequently, an application’s code base should ideally be designed with a queue in mind from the beginning whenever possible to help avoid surprises later.
Scheduling
Another queue use case is scheduling. Priority queues, where certain higher-priority items can be pushed to the back of the queue and then moved to the front based on their order of priority, in particular, are ideal for use cases that involve scheduling.
In scheduling applications, separate queues are maintained for each of the process states, and all processes in the same execution state are placed in the same queue so that processes and threads can be scheduled according to a priority queue, allowing developers to implement applications in a way that allows for efficient utilization of hardware resources and work to be done as quickly as possible.
For example, many operating systems keep a queue of processes for execution. The operating system inspects the process at the front of the queue to determine if it can execute, and the scheduler grants CPU time to a process if it is ready to execute. Once handled, the process is pushed onto the back of the queue again if it’s still running and the schedule continues picking off the queue. This is a simple round-robin scheduler where all processes hold equal priority and every process gets an equal shot at CPU time.
As developers, we often want to allow processes to execute more frequently. Let’s use a process consuming time-sensitive data from a network interface as an example. In this case, we want to give the process reading from the network higher priority so that it executes more frequently and responds faster to the incoming data. A priority queue allows us to achieve this goal by allowing a process to be inserted closer to the head of the queue based on its priority. We still run lower-priority processes inserted at the end of the queue, but the network process will run more frequently because it gets to jump the line a little bit every time. This is of course a simple example. Modern operating systems, particularly those designed for real-time applications, are much more sophisticated, but the basic principles remain the same.
Real-Time Delivery
Real-time data is vital in the finance, media, energy and retail sectors when, for example, developing customer profiles or analyzing financial portfolios, streaming information or predictive IoT device data. While queue data structures are real time in nature, if your server falls behind and is unable to deal with a sudden burst of real-time data, that information could get lost.
In such scenarios, real-time delivery is important. Fortunately, there are queuing brokers that allow for basically an always-on connection to a messaging broker. Once a connection is open, it can listen at all times, which enables rapid response times, but it also means you’re adding costs for a constantly connected service. Plus, that always-connected nature opens up security vulnerabilities.
A Queue in the Form of a Stack
While stack data structures and queue data structures are similar in structure, processors can use a queue natively to implement a stack. Leveraging the last-in, first-out (LIFO) model discussed in part one, when processors call a function, a bunch of state is pushed onto the stack, and then processors can call the next function.
Stack data structures can serve as a sort of temporary memory, often being used as the “undo” buttons in various programs because the most recent changes are pushed into the stack. A commonly used example would be the back button on a browser, with all of the recently visited webpages being pushed into the stack.
As functions are called, the queue is pushing more and more state frames on top of the stack, and then when the functions return, they get popped off, the old states are restored and then a prior function can resume as if nothing happened.
While myriad choices exist for queues across both cloud services and software offerings, it will remain important to consider deployment choices and the correct semantics (e.g., at least once vs. exactly once) for the application, as well as your key metrics and cost drivers.
Equipped with the knowledge of what a queue is and what queues actually do in various computing applications, we can begin to determine what the right queue for your application might be. Check out the next post in this series to learn about the basic cost drivers when choosing a queuing service.